
深度分析Jieba
Jieba
jieba库是一款优秀的 Python 第三方中文分词库
特点
- 支持三种分词模式:
- 精确模式:试图将语句最精确的切分,不存在冗余数据,适合做文本分析
- 全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据
- 搜索引擎模式:在精确模式的基础上,对长词再次进行切分
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
安装说明
代码对 Python 2/3 均兼容
- 全自动安装:
easy_install jieba或者pip install jieba/pip3 install jieba - 半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行
python setup.py install - 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过
import jieba来引用
算法
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
主要功能
jieba.cut方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.lcut以及jieba.lcut_for_search直接返回 list
代码示例:
1 | import jieba |
输出:
1 | [全模式]: 义乌/哥们/名叫/丁/真 |
jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
参数解释:
「strs」: 需要分词的字符串;
「HMM」:用来控制是否使用 HMM 模型;
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用cut和cut_for_search方法都是支持繁体字的。
载入字典
如果是对专业新闻或者小说进行分词,会有很多的新词汇,jieba库里没有就没办法识别,那么就需要添加自定义的词汇,比如:丁真。
添加自定义词汇的方法: jieba.load_userdict(file_name) 参数是文本文件,txt、csv都可以。
自定义词典文件的词汇格式是一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。 比如:
1 | 理塘王 2 |
以”义乌,哥们丁丁丁丁真理塘王” 这段话为例, 如果不添加自定义词典,很多词没办法识别出来。
1 | seg_list = jieba.cut("义乌,哥们丁丁丁丁真理塘王") |
输出:
1 | 义乌/ ,/ 哥们/ 丁丁/ 丁丁/ 真/ 理塘王 |
添加自定义词典后,新词、人名、电影名都可以识别出来
1 | # 载入词典 |
输出:
1 | 义乌/ ,/ 哥们/ 丁丁丁丁真/ 理塘王 |
注意:
如果jieba自己的分词词典dict.txt和自己的定义的字典冲突,会优先用jieba自己的分词词典
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和
dict.txt一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。**file_name** 若为路径或二进制方式打开的文件,则文件必须为UTF-8 编码!!!!。 - 词频省略时使用自动计算的能保证分出该词的词频。
调整词典
- 使用
add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。 - 使用
suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来。 - 注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
1 | print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False))) |
jieba实现基于tf-idf算法的关键词提取
TF-IDF算法介绍
一篇文章的关键词基本都是能体现文章的内容,而且几乎是在文章中频繁出现的词,统计文章中各个词出现的次数,出现最多的则是这篇文章的关键词了,
那具体是怎么统计呢,这里有一个专业术语叫词频(term frequency),简称TF。计算公式如下:
TF(词频) = 某次在文章中出现的次数 / 文章\中的总词数
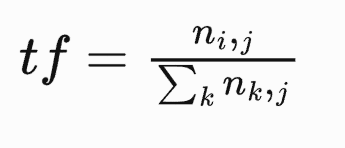
举例子:我正在学习人工智能,并且我一定会成功的。
通过jieba分词得到分词:我/ 正在/ 学习/ 人工智能/ 并且/ 我/ 一定/ 会/ 成功/ 的/
分词之后这句话总共出现9个分词我 2 正在 1 学习 1 人工智能 1 并且 1 一定 1 会 1 成功 1 的 1
我们计算 “人工智能”出现的词频 0.11 = 1/9
但实际上我们肉眼就能判断出有一类词出现的很频繁,
比如“的”、“了”、“在”,显然这类词根本体现不出文章的重要性,肯定不是文章的关键词,这类词有一个专业名词叫停用词(stop words),一般在处理中会将这类词过滤掉。
还有一类词比如阮一峰大神举例中的“中国的蜜蜂养殖”,我们一眼就能看出,蜜蜂、养殖这类词虽然很少,但才是这篇文章的关键词,而“中国”,在各个文章集中经常能见到。“蜜蜂”、“养殖”的权值应该要比“中国”高才对,
分词出现的权重叫做”逆文档频率”(Inverse Document Frequency,缩写为IDF),因此比较经常见到的分词应该给与较低的权限,相反比较不常见的分词则应该给与较高的权重。IDF计算方式是这样的:
IDF = log(语料库出现的文章总数 / 包含该词的文章总数+1),计算IDF的公式并不是唯一的也有其他公式。
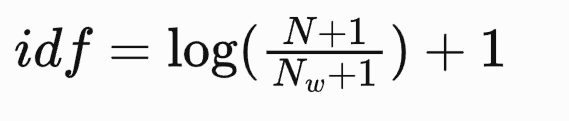
因此 TF-IDF = TF * IDF。值越大表示该词在文章中越重要
通过jieba 的python库提取关键词
jieba 的python插件已经将TF-IDF算法封装好了,因为我们直接引用就可以直接使用。
基于 TF-IDF 算法的关键词抽取方法:
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())sentence 为待提取的文本topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20withWeight 为是否一并返回关键词权重值,默认值为 FalseallowPOS 仅包括指定词性的词,默认值为空,即不筛选
词性对应字符如下表所示:
| 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|
| n | 普通名词 | f | 方位名词 |
| nr | 人名 | ns | 地名 |
| nz | 其他专名 | v | 普通动词 |
| a | 形容词 | ad | 副形词 |
| m | 数量词 | q | 量词 |
| c | 连词 | u | 助词 |
| REP | 人名 | LOC | 地名 |
| s | 处所名词 | t | 时间 |
| nt/ORG | 机构名 | nw | 作品名 |
| r | 代词 | p | 借此 |
| TIME/t | 时间 | w | 标点符号 |
基于tfidf算法的关键词提取代码如下:
1 | import jieba |
 wechat
wechat alipay
alipay

微信号:w1023217219
QQ号:1023217219




