
sklearn.datasets.fetch_20newsgroups下载报错的问题
下载报错的问题
报错
1 | forbidden 403 |
解决方案
- 手动下载正确的安装包
https://ndownloader.figshare.com/files/5975967
- 在我的电脑
C:\Users(你的 user_name)\scikit_learn_data\20news_home 目录下,将下载好的压缩包拖进去(如果之前没有的需要自己手动创建) - python 下载的文件叫20new-sbydate.tar.gz,自己下载的叫20newsbydate.tar.gz,所以需要改文件名字;
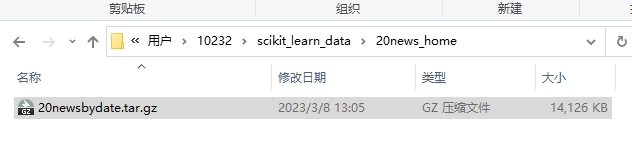
改成->

中间的-一定看清楚!!!
- 通过 D:你的项目下
\venv\Lib\site-packages\sklearn\datasets找到其中的 twenty_newsgroups.py,打开进行如下的修改
python
如果用本机python就找 python 的安装目录
打开文件位置
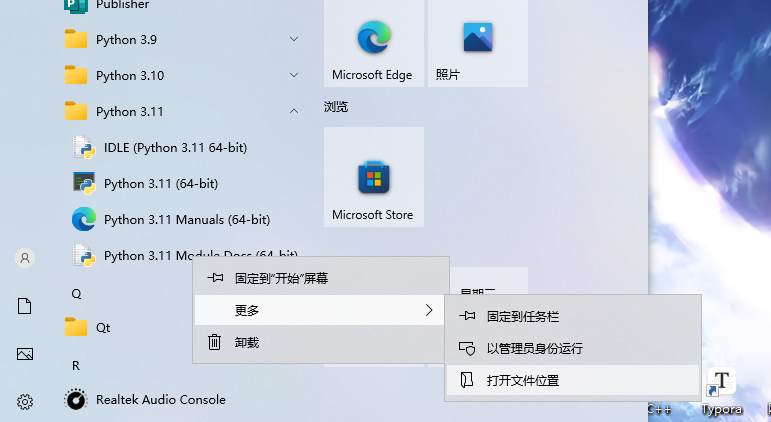
这里打开的只是快捷方式, 再从快捷方式找到实际文件位置
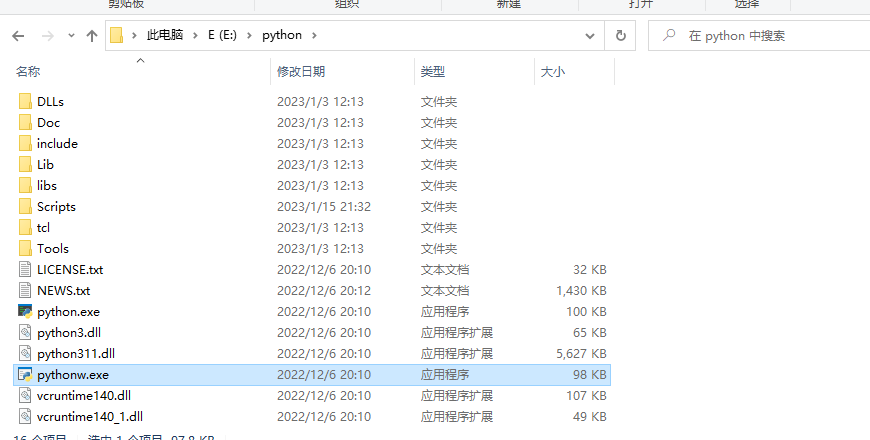
再按流程来
jupyter
如果用的jupyter
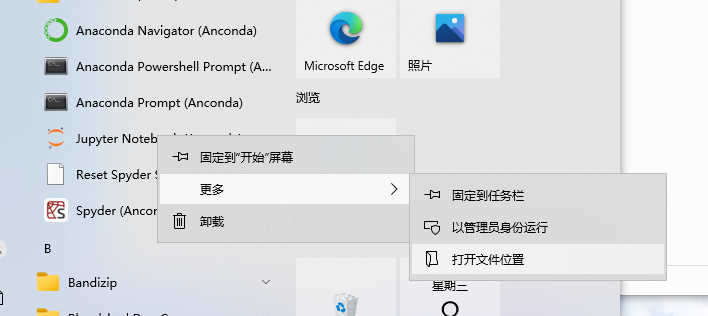
之后流程和python一样
修改文件
查找twenty_newsgroups.py, 文件有多个需要仔细看
找到download_20newsgroups函数
注释掉logger.info("Downloading dataset from %s (14 MB)", ARCHIVE.url)到#os.remove(archive_path)的五句话
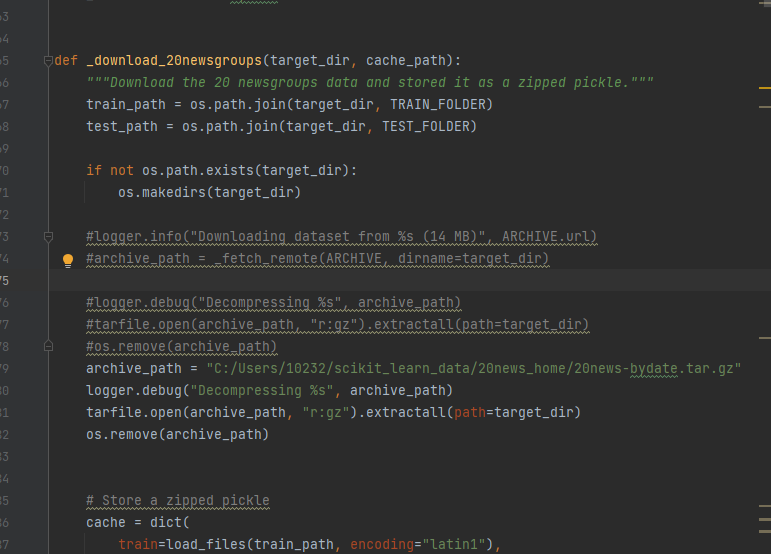
再添加
1 | archive_path = "C:/Users/(你的用户名)/scikit_learn_data/20news_home/20news-bydate.tar.gz" |
注意:archive_path 是刚才放那个压缩包的路径
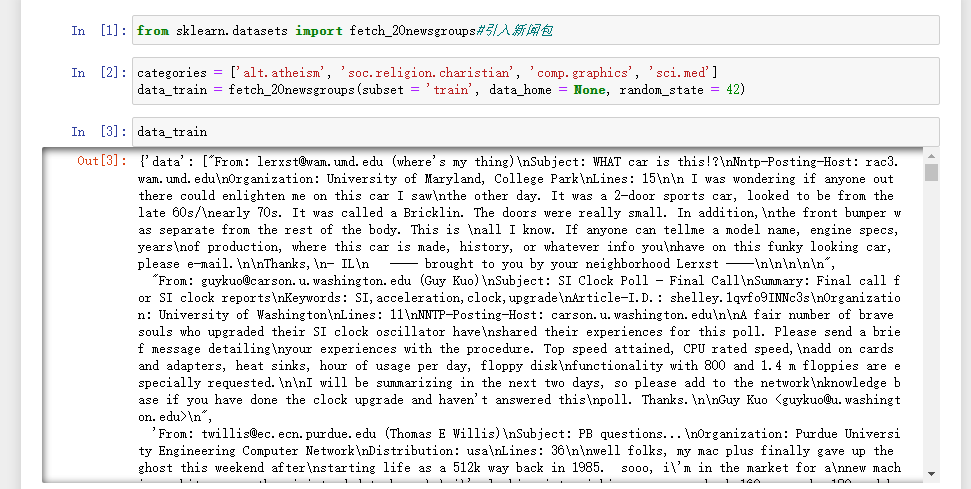
至此,便可以再次运行程序,可以成功运行
压缩文件变成了

发现没有报错
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Abstract1on的博客!
 wechat
wechat alipay
alipay
公告
双 手 合 十 成 为 自 己 的 神, 自 己 所 信 念 的 即 是 信 仰

微信号:w1023217219
QQ号:1023217219




